



With a three year cadence between PCI-Express bandwidth increases and a three year span between when a gear shift is first talked about and when its chippery is first put into the field, it is extremely difficult to not be impatient for the next PCI-Express release to get into the field.
And so, there are a lot of toes tapping as people await PCI-Express 6.0 ports on servers and switches and retimers to extend them and interlink them. But, according to Broadcom, which bought its way into the PCI-Express switching market when its parent company, Avago Technologies, acquired PCI-Express switch maker PLX Technology back in June 2014 for $309 million. That acquisition happened – and before Avago bought Broadcom and took its name in May 2015 for $67 billion – in part because system architects were trying to stuff lots of GPUs, other kinds of accelerators, flash storage, and network interfaces into a server which had too few ports. Hence the need for some kind of switch. Moreover, companies were also looking for a way to aggregate compute at rackscale that had lower latency and lower cost than using InfiniBand and Ethernet networks. PCI-Express switching fit both of the bills.
Flash forward a decade, and it is entirely normal to have lots of PCI-Express switches inside a server and at the top of racks, although Nvidia has done one better with its proprietary NVSwitch architecture, which boasts a lot more bandwidth to couple GPUs and now CPUs together with shared memory inside of a node and even across nodes.
The world wants an open and affordable alternative to NVSwitch for glueing together components to create server nodes or rackscale systems, and PCI-Express switching is central to that. PCI-Express 6.0, which is a particularly pesky speed jump because so many things are changing at the same time because they have to if the bandwidth is to be doubled and the latency is to be help more or less constant with a messier set of error correction needs as signaling rates go up.
As we discussed in detail way back in August 2020, PCI-Express 6.0 moves to PAM-4 encoding (as Ethernet and InfiniBand already have), which gets two bits per signal to effectively double the data rate compared to Non Return To Zero (NRZ) encoding that predates PAM-4 and only has one bit per signal. But PAM-4 has a dirtier signal, with a bit error rate that is three orders of magnitude higher than PCI-Express 5.0 and its NRZ encoding at the same clock speed. The high error rate required forward error correction, or FEC, which adds to latency. Whoops. So the PCI-SIG, lead by Intel, Broadcom, and others, used a mix of flow control unit (FLIT) and cyclic redundancy check (CRC) error detection that only increased latency for small packet sizes and actually reduces latency for large packet sizes by half. Home run!
It is a pity that server platforms and Ethernet and InfiniBand interconnects are refreshed every two years while it is taking three years for PCI-Express ports, retimers, and switches to get into the field – something we have lamented about as an impedance mismatch for a number of years. But it is what it is.
Broadcom has kept to the cadence that the PCI-SIG sets, with multiple generations of its “Atlas” PCI-Express switches and “Vantage” retimers, the latter of which we detailed back in March 2024. The retimers are becoming more and more important because every time you boost the bandwidth on a copper wire by a factor of two, the noise on the wire gets so bad that you can only mitigate the noise by cutting the length of the wire in half. So you need a retimer to boost the signal to push it a distance that used to pretty much come for free with a lower bandwidth.
Here is the roadmap for PCI-Express switches and retimers from last year:
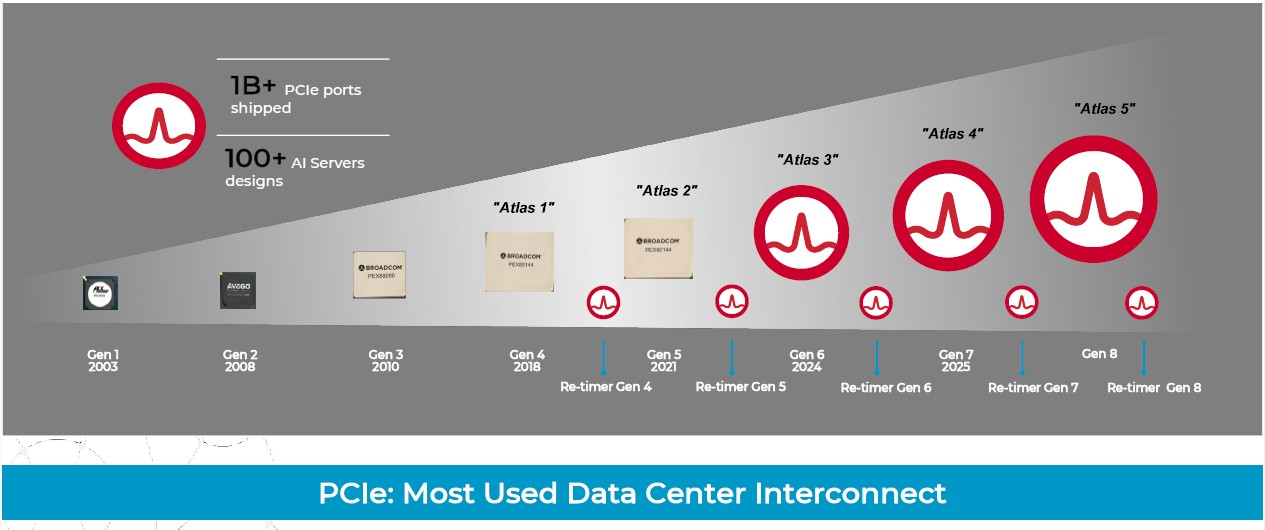
And here is the one that is being released this week:
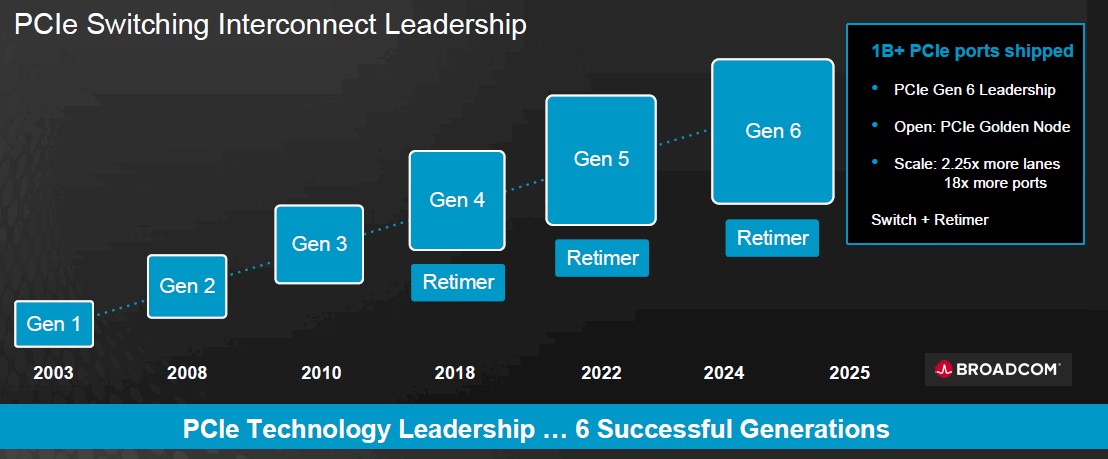
The Vantage 5 retimers support both PCI-Express 5.0 32 Gb/sec NRZ and PCI-Express 6.0 PAM-4 encoding, which is accomplished through the “Talon 5” SerDes created by Broadcom. We strongly suspect that the Talon 5 SerDes are also used in the Atlas 3 PCI-Express switches and provide the PAM-4 support.
For those looking to build more open and cheaper AI and HPC systems, you can imagine that PCI-Express 6.0 cannot get here fast enough. The good news is that it is on track, Sreeni Bagalkote, product line manager for PCI-Express switching at Broadcom’s Data Center Solutions Group, tells The Next Platform. This week, Broad trotted out its PCI-Express 6.0 Interop Development Platform, which includes the “Atlas 3” PEX90144 switch and companion the “Vantage 5” BCM85668A1 retimer, shown in the feature image at the top of this story.
“PCI-Express Gen 6 is probably the most important step function in the PCI-Express world,” says Bagalkote. “We are not just announcing the portfolio of switches and retimers, we are also seeding our partners in the ecosystem with an Interop Development Platform. Gen 6.0 is going to be a tough transition because so many things are changing. That transition will happen first among the testers. Some people have already started building their test equipment using our Atlas 3 switches. And then after that, you will see companies move into manufacturing test, and by the end of the third quarter or the early part of the fourth quarter, you will start seeing manufacturing of systems with Gen 6 devices. The real AI servers with Gen 6 will start ramping up sometime next year.”
Back in the PCI-Express 3.0 days and into the early part of the PCI-Express 4.0 transition, it was Intel, and to a lesser extent, IBM and AMD, that drove the adoption rate for PCI-Express switches and retimers because these were tied to their CPU rollouts. By the PCI-Express 5.0 generation, it was the need for higher bandwidth PCI-Express switches and retimers and the need to cram more accelerators, flash, and network interfaces into an AI server that drove the timing. And with the PCI-Express 6.0 generation, the AI server is the main reason companies are pulling so hard to get the next step function in performance, says Bagalkote. A typical AI server with eight GPUs has four PCI-Express switches, and in the case of Broadcom Atlas 2 and 3 devices, each switch has 144 lanes that are implemented as 72 ports. That is 2.25X more lanes than will be available with alternative PCI-Express 6.0 switches, according to Bagalkote; we are not certain where that data is coming from. (We have not seen PCI-Express 6.0 announcements from Microchip, but they should be coming soon.)
What we do know is that more and faster lanes are needed in a modern AI server, and not just for connectivity, but for telemetry and troubleshooting these complex systems.
“Unlike in traditional PCIe, where all the traffic flows through the CPU, in an AI server there is no central CPU orchestration because AI accelerators are talking to each other with GPUDirect, and using GPUDirect for storage they are talking to the storage. The accelerators and the network interfaces are talking among themselves using peer to peer. So there is a lot of interaction going on between these devices, and the complexity is high. So we not only need to be very robust a PCI-Express switch, but we also discovered that we also, unwittingly and almost by happy accident, became a telemetry and diagnostic hub in most of the AI servers in the world. We have always had a huge amount of debug ability, but our realization is that it is just not enough. We need to enable the AI ecosystem at the rack level to be able to debug, so we kind of coherently stitched all our underlying capabilities and started exposing it to server vendors and also the AI deployers, the hyperscalers.”
The Interop Development Platform is about bringing partners and customers together to build a coherent set of telemetry as well as to make things work.

This interop tool includes the ASICs from Broadcom as well as LeCroy exercisers and analyzers from Teledyne as well as interfaces to flash drives from Micron Technology.
This is all well and good, and we love that PCI-Express is moving along. But we have a thought here. Yes, the PCI-Express switches are good for lashing the flash and NICs to the accelerators and the CPUs in an AI server, or indeed any kind of HPC server or data analytics server.
But perhaps what we need is something that looks and smells a little bit more like NVLink ports and NVSwitches? What about aggregating PCI-Express ports like Nvidia does with NVSwitch? You would need to create a matching NVLink analog on the compute engines so they could be linked to each other or to host CPUs. Something a lot fatter than PCI-Express x16 lane aggregations.
Nvidia has not done as much magic as perhaps it gets credit for with NVLink and NVSwitch. The NVSwitch 4 ASIC, which we detailed back in March 2024, has 57.6 Tb/sec of aggregate bandwidth across an aggregate of 288 lanes running at 200 Gb/sec. Nvidia takes 72 lanes to make an NVLink 5 port, and each NVSwitch 4 therefore has a mere four ports. That NVLink 5 port delivers 1.8 TB/sec of bandwidth, which seems crazy but which is sometimes necessary with AI workloads.
The PCI-Express lanes run at 64 Gb/sec with PCI-Express 6.0, and with an x16 aggregation of lanes, that gives you 256 GB/sec of bandwidth (duplex). If you created what is in a sense an x64 port, you would have 1 TB/sec of bandwidth, and you would have 16 lanes of PCI-Express 6.0 left over to play with for some other use in the 144 lane switch. You could call it PCI-Link 1.0, and then set about to get more bandwidth into the PCI-Express 6.0 switches than they currently have. Throw some CXL memory addressing on the CPUs and GPUs, and you can do coherent memory over it, too.